| Information |  | |
Derechos | Equipo Nizkor
| ||
| Information | | |
Derechos | Equipo Nizkor
| ||
05Feb15
A Guide to Describing the Income Distribution
Contents
Defining Income
Defining Income: Three Areas of Special Consideration
Level of Analysis
How Definitions Affect the Income Distribution: An IllustrationCensus Data
IRS RecordsDescribing a Distribution: The Basics
Describing the Typical Household
Characterizing the Breadth and Shape of the Distribution
The Frequency DistributionQuantiles: Comparing Income Groups
Trends: Making Comparisons over TimeTrends in Median Income
Comparing Income by Geographical Location
The Changing Shape of the Distribution: Mean-to-Median Ratio
Quantile Analysis over TimeVariation in Median Household Income across States
Accounting for Regional Price VariationFigures
Figure 1. Households at the Bottom and Top of the Distribution for Three Census Definitions of Household Income, 2007
Figure 2. Symmetric and Skewed Distributions
Figure 3. Distribution of Household Income, 2013
Figure 4. Median Household Income, 1993-2013
Figure 5. Mean-to-Median Ratio, 1993-2013
Figure 6. Mean Quintile Income, 1993-2013
Figure 7. Income Ratios, 1993-2013
Figure 8. Cumulative Percentage Change in Income Ratios, 1993-2013
Figure 9. Quintile Shares of Total Income, 1993-2013
Figure 10. Cumulative Change in Quintile Shares of Total Income Since 1993
Figure 11. Median Household Income by State, 2013
Figure 12. BEA Regional Price Parities by State, 2012
Figure 13. The Relationship Between the Lorenz Curve and Gini Index
Figure 14. Two Lorenz Curves with the Same Gini Index
Figure 15. Gini Index for the United States, 1993-2013
Figure A-1. Mean After-Tax Income within the Top Income Quintile, 2011Tables
Table 1. Three U.S. Census Bureau Household Income Definitions
Table 2. Quantile-based Measures of Household Income Dispersion, 2013Appendixes
Appendix A. Describing Incomes at the Top of the Distribution
Appendix B. Summary Indicators Reported by Census
Summary
The distribution of income in the United States features heavily in congressional discussions about the middle class, program funding and effectiveness, new and existing target groups, government tax revenue, and social mobility, among other topics. Recently, the level and distribution of U.S. income have also been raised in the context of broader macroeconomic issues, such as economic growth. Accordingly, Congress has sought information on the absolute and relative experience of U.S. households, the range of incomes, and their dispersion.
Describing the income distribution involves several important choices about the definition of income and the level at which income data are examined. Income can be constructed narrowly (e.g., earnings only) or broadly (e.g., as the sum of earnings, capital gains, government transfers, and other sources); it can be presented in pre-tax status or reflect taxes paid and tax credits received. Income can be presented at the individual level or represent pooled resources among households, families, or tax units. These choices about how to define income affect the magnitude of income indicators and the shape and range of the U.S. income distribution. For this reason, disagreement over the interpretation of income levels and trends frequently centers on how income is defined.
This report is a guide to various measures, indicators, and graphics commonly used to describe the U.S. income distribution. It examines the complexities of income measurement, outlines important definitional and data considerations to bear in mind when using and interpreting income statistics, and reviews descriptive statistics commonly used in analysis. It also discusses the Gini index, a popular summary measure of income dispersion and an appendix presents information on additional summary indicators of income dispersion reported annually by the U.S. Census Bureau.
The report provides descriptive analysis of the U.S. income distribution to illustrate various concepts and data presentation strategies. This analysis reveals broad trends, but does not provide an exhaustive study of the distribution of income in the United States. Importantly, the report does not explore potential drivers and impacts of changes to the shape and span of the distribution.
Census data show a gap in income between households at the top of the distribution and those in the middle and bottom of the distribution. In 2013, household income at the 90th percentile was $150,000, whereas household income at the 10th percentile was $12,401. Said another way, household income at the 90th percentile was 12.1 times the level of household income at the 10th percentile. Median household income in 2013 was $51,939, up from $49,594 in 1993 (in 2013 dollars).
Census data reveal growing concentration of income at the top of the distribution between 1993 and 2013. Households in the top 20% of the distribution earned 51% of total household income in 2013, compared to 48.9% in 1993 (an increase of 4.3%). The share of total income among the bottom 20% of households was 3.2% in 2013 and 3.6% in 1993 (a decrease of 11.1%). In addition, Census calculations indicate that the Gini index increased from 0.454 in 1993 to 0.476 in 2013, indicating increased dispersion of household income.
The distribution of income in the United States features heavily in congressional discussions about the middle class, program funding and effectiveness, new and existing target groups, government tax revenue, and social mobility, among other topics. Recently, the level and distribution of U.S. income have also been raised in the context of broader macroeconomic issues, such as economic growth.
Recent congressional activity--committee hearings and reports, communication with major media outlets, and policy research discussions about income--reveals a heightened interest among some Members in the distribution of U.S. income. This report responds to that interest by providing a guide to various measures, indicators, and graphics commonly used to describe the U.S. income distribution. |1|
This report provides descriptive analysis of the U.S. income distribution to illustrate various concepts. This analysis reveals broad trends, but does not provide an exhaustive study of the distribution of income in the United States. Importantly, the report does not explore potential drivers and impacts of changes to the shape and span of the distribution.
This report is organized as follows: first, it examines the complexities of income measurement and important definitional and data considerations to bear in mind when using and interpreting income statistics. Next, it describes two popular data sources used to study the U.S. income distribution, followed by sections on statistics commonly used to provide point-in-time analysis and to compare U.S. income across groups, time, and location. The report concludes with an explanation of the Gini index. An appendix presents information on the set of summary indicators of income dispersion reported annually by the U.S. Census Bureau.
On the surface, measuring income is a simple concept. |2| In practice, however, empirical analysis of the income distribution involves several choices about how income is defined and the level at which income data are examined. Income can be constructed narrowly (e.g., earnings only) or broadly (e.g., as the sum of earnings, capital gains, government transfers, and other sources). It can be presented in pre-tax status or reflect the taxes paid and tax credits received. Income can be measured at the individual level or represent pooled resources among households, families, or tax units.
These choices about how to define and organize income are consequential, because the same data can present different pictures of the income distribution depending on how income is constructed. |3| Among commonly used income definitions, movement from one income measure to another is unlikely to shift household rankings dramatically--that is, the poor are not likely to be characterized as rich, or vice versa--but poor households might not look quite as poor when the value of government transfers are included, and the level and movement in incomes at the top of the distribution will depend importantly on whether and how capital gains and personal income taxes are included. The level of income analysis--that is, whether income is measured at the individual, household, or family level--will also impact indicators used to characterize the income distribution. For example, average individual income will lie below average household income, simply because households can have multiple earners. For these reasons, disagreement over the interpretation of income levels and trends frequently centers on how income is defined.
Income can be seen through many lenses. It can refer simply to earnings (i.e., wages, salaries, and self-employment earnings) or to more expansive measures that span several sources of cash income and in-kind benefits and account for taxes paid and tax credits. One income formulation is not necessarily superior, as there may be valid reasons for selecting one definition over another. For example, a restrictive measure may be preferred when assessing trends and outcomes for a particular family of income streams (e.g., how market income is distributed among households). A comprehensive measure, however, may make more sense when examining households' overall ability to use income to meet basic needs. |4|
Recognizing a lack of consensus on how to define income and the benefits of definitional flexibility for certain types of analyses, the Census Bureau makes several income formulations available to data users. In addition to the money income definition it uses to produce official income dispersion estimates, Census provides annual estimates of market income, post-social insurance income, disposable income, and an income measure recommended by the National Academies of Science. Census also allows data users to customize an income measure for certain statistics by specifying which of the 42 Census income components to include. |5|
Table 1 compares three Census-defined income measures and illustrates the variability of income concepts. The first column shows money income, the income definition used by Census to calculate annual income dispersion estimates. Money income represents pre-tax cash income received on a usual basis by households; notably, it excludes occasional income such as capital gains (and losses) and in-kind benefits. Market income (second column) is a somewhat narrower concept that reflects pre-tax income from market sources. Disposable income (column three) is the most expansive formulation in the table. In addition to all components in money and market income, it includes receipt of the Earned Income Tax Credit (EITC); Supplemental Nutritional Assistance Program (SNAP); free, reduced, and regular-price school lunches; public housing and rental subsidies; and economic stimulus payments (in 2009 only) and recovery payments (in 2010 only). It deducts federal and state income taxes that remain after receipt of refundable tax credits, payroll taxes, and property-taxes on owner-occupied housing.
Defining Income: Three Areas of Special Consideration
Table 1 highlights a few points that arise regularly in research and policy discussions around the U.S. income distribution. These include whether and how to account for capital gains and losses, tax deductions and credits, and government-supported health insurance. How these components are treated is consequential for income distribution analysis because they are experienced differently by low-, middle-, and high-income individuals and households. This means the difference between including these components in income and not including them in income is not a mere shift in the distribution, but potentially alters the shares of total income held by various income groups, and where an individual or household ranks in the distribution.
Accounting for Capital Gains and Losses
One notable difference between the Census money income concept and the two alternative definitions presented in Table 1 is the treatment of capital gains. |6| Money income, the definition used by Census to generate its annual income dispersion statistics, does not include capital gains and losses at all. This is frequently identified as a limitation of official Census income statistics in accurately characterizing U.S. income levels, distribution, and trends, because capital gains can be a significant source of income, particularly among households at the upper end of the distribution. |7|
The Internal Revenue Service (IRS) income tax return data record capital gains only when the gains are realized and reported as part of taxable income. For these data, capital gains may therefore be more visible among high-income households because they are more likely to hold (and sell) assets that produce taxable income. In addition, some contend that the standard onetime valuation of capital gains income in the year of realization (i.e., sale of asset) is misleading. |8|
This is because the value of assets can accrue over the course of several years, contributing incrementally to available resources. The counter perspective is that continuous accounting for capital gains is a purely theoretical exercise, noting that (1) living standards do not rise with asset value accrual, and (2) the view that available resources rise with asset appreciation rests on the assumption that households can obtain peak prices for their assets. |9|
Pre-tax versus Post-tax Income
The treatment of taxes (i.e., payments and credits) is another point of consideration highlighted in Table 1. Unlike money income and market income, disposable income presents income in post-tax status, taking into account payment of personal income taxes and receipt of tax credits. It could be argued that this income formulation provides a more realistic representation of income available for consumption in a given year. It also affects the measurement of the income distribution because tax payments and credits are likely to be experienced differently by lower-and higher-income groups. Some low-income individuals and households may not meet the earnings threshold for taxable income or otherwise have a disproportionately lower tax bill than their middle- and high-income counterparts. Likewise, low-income individuals and households are more likely to qualify for certain tax credits, such as the EITC. For these reasons, post-tax income formulations are likely to raise incomes among low-earners and reduce incomes among high-earners when compared with similar pre-tax income definitions. |10|
The Value of Government-Supported Health Insurance
The value of government-supported health insurance--such as Medicare and Medicaid--is a facet of income that is not reflected in any of the Census income definitions summarized in Table 1. Given its potentially sizable impact on the availability of household resources, income estimates that do not account for government health insurance have been criticized for providing a misleading picture of the income distribution. One concern is that some government-supported health benefits (e.g., Medicaid) are received disproportionately by lower-income individuals and households. Excluding this component may therefore understate the full value of resources among the low-earner group relative to those in the middle and top of the distribution. |11|
Table 1. Three U.S. Census Bureau Household Income Definitions
Money
IncomeMarket
IncomeDisposable
IncomeIncome Components Earnings (wages, salaries, and self-employment income) x x x Interest income x x x Dividend income x x x Rents, royalties, estate, and trust income x x x Nongovernment retirement pensions and annuities x x x Nongovernment survivor pensions and annuities x x x Nongovernment disability pensions and annuities x x x Realized capital gains xa xa Social Security x x Unemployment compensation x x Workers' compensation x x Veterans' payments other than pensions x x Government retirement pensions and annuities x x Government survivor pensions and annuities x x Government disability pensions and annuities x x Public assistance (includes TANF and other cash welfare) x x Supplemental Security Income x x Veterans' pensions x x Federal earned income credit x Government educational assistance x x Nongovernment educational assistance x x x Supplemental Nutritional Assistance Program x Free and reduced-price school lunches x Public housing and rental subsidies x Child Support x x x Alimony x x x Regular contributions from persons not living in the household x x x Money income not elsewhere classified x x x Imputed return to home equity on owner-occupied housing x x Regular-price school lunches x Economic stimulus payments (2009 ASEC only) x Economic recovery payments (2010 ASEC only) x Deducted from Income Realized capital losses xa xa Federal income taxes after refundable credits except EIC x State income taxes after all refundable credits x Payroll taxes (FICA and other mandatory deductions) x Property taxes on owner-occupied housing x Work-related expenses excluding child care x x Source: Table prepared by the Congressional Research Service (CRS) using U.S Census Bureau definitions, available at http://www.census.gov/cps/data/incdef.html.
a. The last year for which capital gains and losses estimates are available from the Census Bureau is 2007 (data collected in 2008).How Definitions Affect the Income Distribution: An Illustration
Figure 1 presents the percentage of U.S. households with no income in 2007 (left side) and the percentage of households that earned $100,000 or more in 2007 (right side), when the three definitions in Table 1 are applied to Census data. The data year 2007 was selected for Figure 1 because that is the last year that Census produced estimates for capital gains and losses (see footnote 6).
When the most restrictive measure--market income--is applied, Census estimates show that 4.0% of households had zero income in 2007. This measure falls to 1.2% when the money income definition is applied, reflecting the value of government cash transfers on incomes at the bottom of the distribution. The disposable income definition, which takes a fuller range of government benefits and federal and state taxes (payments and credits) into account, produces the fewest no-income households (0.5%).
Movement from the most restrictive income definition (market income) to the most expansive income definition (disposable income) produced a smaller and smaller number of households with no income in 2007; that is, it appears to raise incomes at the bottom of the distribution. The opposite pattern is observed at the top of the distribution: the addition of income dimensions to the income definition appears to reduce the number of households with high incomes. The market income and money income definitions produce nearly identical percentages of households with $100,000 or more in 2007 (20.4% and 20.3%, respectively). The group of high-earning households is smallest at 11.8%, when the broadest definition, disposable income, is used.
Figure 1. Households at the Bottom and Top of the Distribution for Three Census

Click to enlargeSource: Figure created by the Congressional Research Service (CRS) using data from the U.S. Census Bureau CPS Table Creator, available at http://www.census.gov/cps/data/cpstablecreator.html.
Income can be presented at the individual level or represent pooled resources among families, households, or tax units. Although synonymous in regular discourse, family and household concepts can have important distinctions for statistical purposes. The Census Bureau defines a family as two or more people with a direct familial relationship (i.e., related by birth, marriage, or adoption), and a household as one or more people who live together and may or may not be related. A household may be a single person, a collection of roommates, or one or more families living together. Tax units are an IRS concept and describe the person or persons filing a tax return (i.e., individual filer and dependents or married filers and their dependents). A tax unit can represent an individual, an entire household or family, or several tax units can reside within a household or family.
The income distribution will look different depending on whether it is organized at the individual level or household (or other aggregate) level. Individuals (and single tax units) are more numerous and have lower average income levels than households and families, because the latter groups can have multiple earners. Individual income analysis will reveal more low-income persons--such as college students with summer jobs--who are otherwise aggregated into household or family income measures. For these reasons, income analyses that organize income at the individual level are not directly comparable with those that use data on multi-member units that may pool resources.
Comparability issues affect income data organized at multi-member levels as well. For example, the number of members can vary considerably across households, families, and tax units, complicating comparisons of per-person resources. That is, a member of a four-person household with an income of $52,000 does not have the same access to resources as a two-person household earning $52,000 in the same year. The composition of units also matters to how resources are pooled and shared across members. For example, a mother-child household is likely to share resources differently than two adult unrelated roommates. Some researchers and organizations adjust data in response to these issues. |12|
The potential for meaningful income distribution analysis rests on the quality and coverage of the underlying data. Government sources often offer the best option, given the scale of effort, cost, and sensitive nature of collecting income information. |13| Census Bureau household survey data and IRS tax return administrative data are two main sources of annual data used to characterize and study the U.S. income distribution. |14| Both agencies publish official statistics on an annual basis and offer some public access--with restrictions--to the individual records. Census and IRS data have relative strengths and important individual limitations that affect their potential to fully characterize the U.S. income distribution. |15|
The U.S. Census Bureau collects income data annually from a random sample of households through the Current Population Survey (CPS) Annual Social and Economic Supplement (ASEC). Data are collected from February to April of each year and measure income from the previous calendar year. |16| Census compiles official income statistics based on these data and publishes them in the annual Income and Poverty in the United States report. |17|
Census reports statistics on money income, which represents pre-tax cash income received by households on a regular basis from market and nonmarket sources. In addition to regular market income, money income as defined by Census includes the value of all public cash transfers (e.g., Temporary Assistance for Needy Families [TANF]). It excludes periodic income, such as capital gains, and in-kind transfers (e.g., Supplemental Nutritional Assistance Program [SNAP] benefits and employer contributions to health insurance plans). (See Table 1.)
Some aspects of the Census Bureau CPS-ASEC data limit its usefulness in characterizing households at the top of the distribution. To start, Census income estimates are based on information collected from a random sample of households; survey responses are extrapolated to population estimates using sample weights. This method tends to be most effective for estimating the level and distribution of income among middle- and low-income households, where households are clustered together and income ranges are relatively narrow. Estimates at the top, however, where incomes are spread much farther apart, can be quite sensitive to sample composition.
Data recording and internal processing procedures introduce further restrictions on top incomes in the CPS-ASEC data. |18| Census limits the number of digits available to survey interviewers when recording individual responses to income questions, effectively capping the level of income that can be reported. This limit was raised from $299,999 to $9,999,999 for each of the four earned-income sources in 1994, when Census moved from a pen-and-paper data collection method to a computer-assisted interview. |19| This means that during the interview, if an individual reports earned income of $10 million or more, it will be recorded by the enumerator as $9,999,999. Once collected, Census edits its income data to minimize the incidence of interviewer error or misreporting on the part of the individual interviewed. For the purposes of Census-published data tabulations and public-use data, the internal processing limit is $999,999 for each of the four individual earnings categories. |20| Finally, Census has historically faced problems in capturing accurate information on interest and dividend income, which is disproportionately received by high-income households. |21|
In addition, the CPS-ASEC survey has undergone several methodological changes that compromise comparability of income estimates over time. These include the periodic update of Census weights, the addition of new income categories, and changes in recording limits. The Census Bureau is careful to note these changes for published statistics in detailed table footnotes.
IRS records capture information on pre-tax, pre-transfer taxable income from a large sample of households, and are viewed as a superior data source for examining the top of the income distribution. Unlike the Census CPS-ASEC, IRS data are based on administrative records (i.e., tax returns filed by tax units) and do not represent a random sample. IRS systematically collects data on taxable income from all individuals who are required to file. Its sample is therefore individuals (or units) with taxable income who comply with federal tax law.
IRS data provide a better view of incomes at the top, because this group is almost universally required to file. |22| However, it has less coverage among low-income individuals and households since some low-income individuals and families are not required to file tax returns at all. It may also undercount income received by this group because certain types of government assistance provided predominantly to lower-income households are not reported on federal tax returns (e.g., SSI and TANF payments). In addition, the types of capital gains realized most often by middle-and lower-income filers tend to be untaxed (e.g., from sale of residential property) and therefore unreported on tax returns.
IRS data also do not offer perfect comparability over time. Changes to the federal tax code affect how income is reported (e.g., as personal versus business income), the types of income that are taxable, and who is required to file. Tax code changes can also stimulate household behavior with consequences for taxable income. This may include the strategic sell off of assets in anticipation of higher capital gains taxes. |23| It may also affect labor supply decisions, and hence earnings, although the literature offers no clear guidance on how labor supply responds to tax code changes in practice. |24|
Analyses in subsequent sections of this report employ U.S. Census Bureau statistics on household money income, collected through the CPS-ASEC and published annually in the Census Bureau report Income and Poverty in the United States. |25| The exception is Appendix Figure A-1, which shows data compiled by the Congressional Budget Office (CBO). The Census definition of money income describes regular, pre-tax cash income from market and nonmarket sources. It excludes capital gains and in-kind forms of income (e.g., noncash government benefits, goods produced and consumed at home or farm, employer contributions). Income is observed and described at the household level.
Data for 2013 are used to illustrate point-in-time measures. |26| When indicators are considered over time, the report uses the time period 1993-2013. The base year for time series comparisons is set to 1993 because significant methodological changes affect the comparability of Census income measures before and after 1993.
All data are reported in 2013 dollars. Income levels from 1993 to 2012 are adjusted (by Census) using the Consumer Price Index Research Series using Current Methods (CPI-U-RS),which applies various methodological improvements to the Bureau of Labor Statistics (BLS) Consumer Price Index for all Urban Consumers (CPI-U). |27|
Describing a Distribution: The Basics
Even in their simplest forms, descriptive statistics can provide insight to the income of the "typical" household and characterize the full spread of incomes, offering a meaningful starting point to policy discussions about household income.
Describing the Typical Household
The mean and median are the main measures used to describe the center of a distribution and are prime candidates for describing the experience of the typical household. Mean income is obtained by dividing total aggregate household income by the total number of households, that is, the simple average or the level of income that each household would have in hand if total income were distributed equally. It is particularly useful as a measure of central tendency when the distribution is symmetrical, but loses power as a measure of the typical household's income when the distribution is skewed and in the presence of outliers. |28|
The median is generally viewed as a better indicator of typical household income. It is the level of income that divides the population into two equal-sized groups: the lowest 50% of households (who earn less than the median value of income) and the top 50% of households (who earn more than the median value of income). For example, the Census Bureau estimates that median household income in the United States was $51,939 in 2013. This means that in 2013, approximately 50% of households had incomes above $51,939 and 50% of households earned less than $51,939. For reference, mean household income was $72,641 in 2013.
To see the relative merits of the median as a measure of the typical household, consider the following example. Ten households line a street, each with an annual income of $52,000. Median and mean annual household income are therefore both $52,000 for this street. On January 1 of the next year, the 10th house wins the lottery, paid through an annuity that raises its annual income to $200,000. In an instant, mean household income for this street has increased from $52,000 to $66,800, while the median remains $52,000. Despite this increase in mean household income, the situation of 90% of households is unchanged, because households on this street do not pool resources. Instead the median conveys more accurate information on typical household income for this population.
Characterizing the Breadth and Shape of the Distribution
Information on breadth of earnings and the placement and concentration of households along the income spectrum is interesting from a policy perspective. The distributional range, the difference between the highest and lowest value, is arguably the simplest measure of dispersion. In terms of household income, it is the difference between the income of the richest household and income of the poorest household. |29| Despite the simplicity of the indictor, data collection methods and statutory privacy rules make calculating the range nearly impossible. Consequently, no official data are publicly available on the absolute highest and lowest income households in the United States. See Appendix A for a discussion of incomes at the top of the distribution.
The shape of the income distribution reveals how households line up and cluster along the spectrum of incomes. The shape of a distribution can be described as symmetric, right-skewed or left-skewed. Symmetric distributions (Figure 2, Panel A) are balanced, with the center of the data in the center of the graph. Because the "tails" of the distribution (i.e., the few households at the very top and very bottom of the distribution) balance each other out, the mean and median values are identical or very close to each other. Skewed distributions are asymmetric and characterized by a mass of observations (e.g., households) to one side of the graph with either a long or thick tail to the other side. When the mass of households are found clustered toward the bottom of the distribution, with a tail to the right, the distribution is said to be right-skewed or positively skewed (Figure 2, Panel B). The group of relatively high incomes at the top pulls up the mean, so that it will exceed the median in right-skewed distributions. The distribution is left-skewed or negatively skewed when mass is concentrated among high values, with the tail leading to the left (Figure 2, Panel C). The mean in left-skewed distributions is pulled down by the relatively low-income households that form its tail, and it will lie below the median. Income distributions are typically right-skewed.
Figure 2. Symmetric and Skewed Distributions

Click to enlargeSource: CRS.
Graphical representations of an income distribution, such as the frequency distribution in Figure 3, can convey information about central tendency (mean and median), shape, and range in a concise and intuitive way. Figure 3 shows the distribution of U.S. household income in 2013. It plots income levels on the horizontal axis and the percentage of households on the vertical axis, and shows a right-skewed distribution. In 2013, median household income was $51,939 and average household income was $72,641.
As noted earlier, Census does not provide a lot of detail on the income levels and the distribution of high-income households. This is reflected in Figure 3, which divides U.S. households into several income "bins" based on their money income in 2013. Between $5,000 and $199,999, incomes are grouped in bins with a $5,000 range. At $200,000, the scale changes: the penultimate bin has a range of $200,000 to $249,999 and the final bin includes all incomes at $250,000 and over. The first bin (under $5,000) has a range in excess of $5,000 because it includes negative income values. |30|
Figure 3. Distribution of Household Income, 2013

Click to enlargeSource: U.S. Census Bureau, Annual Social and Economic Supplement, available at http://www.census.gov/hhes/www/cpstables/032014/hhinc/toc.htm.
Notes: Income in this figure refers to household money income as defined by the Census Bureau: pre-tax cash income received by households on a regular basis from market and nonmarket sources. Money income excludes periodic income, such as capital gains, and in-kind transfers. Due to the way the Census Bureau aggregates incomes at the top of the distribution, the top two income groups--"$200,000 to $249,000" and "$250,000 and over"--represent wider income ranges than the groups that categorize the majority of the distribution. The "Under $5,000" group includes households earning zero or negative money income.All of the indicators presented so far can be used to examine how income varies across income groups, time, or location. This type of analysis can inform discussions around changing program participation patterns, differential access to resources across groups and locations, trends in the absolute and relative experience of U.S. households, and efforts to foster social mobility.
Quantiles: Comparing Income Groups
Recent conversations about income in the United States tend to draw comparisons between income groups (e.g., top, middle, and bottom income households). Quantiles are a helpful tool for such cross-group analysis. They divide households--ordered by income from lowest to highest-- into groups of equal size (i.e., equal number of households) and provide a means for defining the top, middle, and bottom of the income distribution. Once defined, incomes can be compared and contrasted across and within income groups. Commonly used quantiles include quartiles, which divide the population into quarters, quintiles, which divide the population into fifths, and deciles and percentiles, which divide the populations into tenths and hundredths, respectively.
Quantiles divide the population into groups with the same number of members (e.g., households, individuals); however, they do not necessarily divide individuals or households into equally spaced income brackets. Where households are clustered together, traditionally at the bottom and middle of the distribution, the income range for quantiles is likely to be smaller (sometimes much smaller) than the income range at the very top of the distribution, where households are spread far apart.
The Census Bureau publishes several quantile-based measures of income dispersion each year, including household income at selected percentile limits, income ratios of selected percentiles, mean income by quintile, and share of total household income held by quintiles. Table 2 provides selected Census measures for 2013.
Income percentile limits (Table 2, Panel A) report the level of household income at various dividing points of the income distribution. For example, the 50th percentile limit is the level of income that divides the population in half (i.e., the median). Income at the 90th percentile limit indicates that the bottom 90% of households received less than $150,000 in 2013, while the top 10% of households received more than $150,000. A comparison of percentile limits at the 80th and 20th percentiles reveals that the 60% of households in the middle of the distribution received money income between $20,900 and $105,910 in 2013.
An income ratio (Table 2, Panel B) is a relative measure that expresses income at one percentile limit as a multiple (or fraction) of income at another percentile limit. For example, the 90th/10th income ratio was 12.10 in 2013. This number is calculated by dividing the household income at the 90th percentile ($150,000) by that at the 10th percentile ($12,401). It indicates that the 90th percentile household took in money income that was just over 12 times the money income received by the household at the 10th percentile.
Census reports two sets of statistics that describe household income quintiles (Table 2, Panel C). Quintile mean income is the average income of households within a given quintile, calculated by dividing total quintile income (i.e., the sum of all household income within a quintile) by the number of households in the quintile. As expected, quintile mean income rises throughout the distribution, with the largest jump in mean income between the 4th and 5th quintiles.
The quintile share of total income describes the percentage of total income held in aggregate by members of a given quintile. It is the ratio of total quintile income to total income for all households. In 2013, the bottom 20% of households (i.e., the lowest quintile) received 3.2% of total household money income, the middle 60% (the sum of shares for the second, third, and fourth quintiles) received 45.8%, and the top 20% of households received 51%. For reference, because each quintile represents 20% of the population of households, a 20% income share in each quintile would represent a mathematically equal distribution of household income.
Table 2. Quantile-based Measures of Household Income Dispersion, 2013
A. Household Income at Selected Percentile Limits 10th Percentile $12,401 20th Percentile $20,900 50th Percentile (Median) $51,939 80th Percentile $105,910 90th Percentile $150,000 95th Percentile $196,000 B. Income Ratios of Selected Percentiles 90th/10th Income Ratio 12.10 90th/50th Income Ratio 2.89 50th/10th Income Ratio 4.19 C. Quintiles Incomes Quintile Mean Share of Total
Household IncomeLowest Quintile $11,651 3.2 Second Quintile $30,509 8.4 Third Quintile $52,322 14.4 Fourth Quintile $83,519 23.0 Top Quintile $185,206 51.0 Source: Table created by CRS based on data from U.S. Census Bureau, Current Population Survey, Annual Social and Economic Supplement, 2013, available at http://www.census.gov/hhes/www/income/data/index.html.
Notes: Income in this table refers to household money income as defined by the Census Bureau: pre-tax cash income received by households on a regular basis from market and nonmarket sources. Money income excludes periodic income, such as capital gains, and in-kind transfers.Trends: Making Comparisons over Time
This section provides several examples of how to present and interpret income comparisons over time. A common data source is used to calculate statistics compared over time, with minor year-to-year changes in data collection and processing methodology. However, a common source is not always available for certain comparisons. In these cases it is tremendously important to note any divergence in data source, level of data organization (e.g., household versus family), definitions, and relevant methodological chances. Without appropriate caveats, these methodological and definitional differences can be interpreted erroneously as changes (or lack of change) in actual income, and provide misleading information.
Simple indicators like median income can be used to describe the experience of the typical household over time. Figure 4 shows the trend in median household income between 1993 and 2013. Overall, real median household income increased from $49,594 in 1993 to $51,939 in 2013, with notable fluctuation over this period. A pattern of declining median income during periods of economic recession can be observed for the 2001 and 2007-2009 recessions. Median household income in 2013 was slightly higher than median household income in 1995 ($51,719 in 2013 dollars).
Figure 4. Median Household Income, 1993-2013
(in 2013 CPI-U-RS adjusted dollars)

Click to enlargeSource: Figure created by CRS based on data from U.S. Census Bureau, Current Population Survey, Annual Social and Economic Supplements, l993-20l3, available at http://www.census.gov/hhes/www/income/data/index.html.
Notes: Income in this figure refers to household money income as defined by the Census Bureau: pre-tax cash income received by households on a regular basis from market and nonmarket sources. Money income excludes periodic income, such as capital gains, and in-kind transfers. Periods of recession are shaded in gray. Recession data are from the National Bureau of Economic Research, http://www.nber.org/cycles.html, and reflect the 2001 recession (March 2001 -November 2001) and the 2007-2009 recession (December 2007-June 2009).The Changing Shape of the Distribution: Mean-to-Median Ratio
As noted in the discussion of Figure 2, the shape of the distribution affects the relative position of mean and median. Drawing on this relationship, the mean-to-median ratio can be used to convey big picture information about the shape of distribution. When a distribution is symmetrical, mean and median will be the same (or very close), and the mean-to-median ratio will be one. The mean exceeds the median for a right-skewed distribution, characterized by a mass of observations on the left side of the graph and a tail to the right, yielding a mean-to-median ratio that exceeds one. |31|
Observed over time, the mean-to-median ratio provides information about the extent to which the mean is approaching or retreating from the median, and can be used to gauge changes to the shape of an income distribution. Figure 5 plots the mean-to-median ratio from 1993 to 2013. For all years, the mean-to-median ratio is greater than one, indicating a right-skewed distribution throughout the time period. Between 1993 and 2013, both mean and median income increased in real terms (not shown in Figure 5), but growth in average income outpaced growth for the median. |32| This is captured by the rise in the mean-to-median income from 1.33 to 1.40. In terms of the shape of the distribution, a rising mean-to-median ratio suggests an increasingly right-skewed distribution. |33|
Figure 5. Mean-to-Median Ratio, 1993-2013

Click to enlargeSource: Figure created by CRS based on data from U.S. Census Bureau, Current Population Survey, Annual Social and Economic Supplements, 1993-2013, available at http://www.census.gov/hhes/www/income/data/index.html.
Notes: Income in this figure refers to household money income as defined by the Census Bureau: pre-tax cash income received by households on a regular basis from market and nonmarket sources. Money income excludes periodic income, such as capital gains, and in-kind transfers. Periods of recession are shaded in gray. Recession data are from the National Bureau of Economic Research, http://www.nber.org/cycles.html, and reflect the 2001 recession (March 2001-November 2001) and the 2007-2009 recession (December 2007-June 2009).Quantile trend analysis can reveal changing patterns in the absolute and relative experience of U.S. households. Figure 6 presents mean quintile household income from 1993 to 2013. A few points of interest can be taken from this graph. First, mean income among the top quintile is markedly above the other four quintiles for the duration of the observed period. In all years, mean income among the top quintile was at least twice as large as the mean income in the fourth quintile. Second, mean income increased for the 2nd, 3rd, 4th, and top quintiles over this time period--though the rate of growth in mean quintile income becomes steadily smaller when moving from the top quintile to the second quintile. |34| Finally, quintile mean income growth stalls or declines during periods of recession.
Figure 6. Mean Quintile Income, 1993-2013
(in 2013 CPI-U-RS dollars)

Click to enlargeSource: Figure created by CRS based on data from U.S. Census Bureau, Current Population Survey, Annual Social and Economic Supplements, l993-2013, available at http://www.census.gov/hhes/www/income/data/index.html.
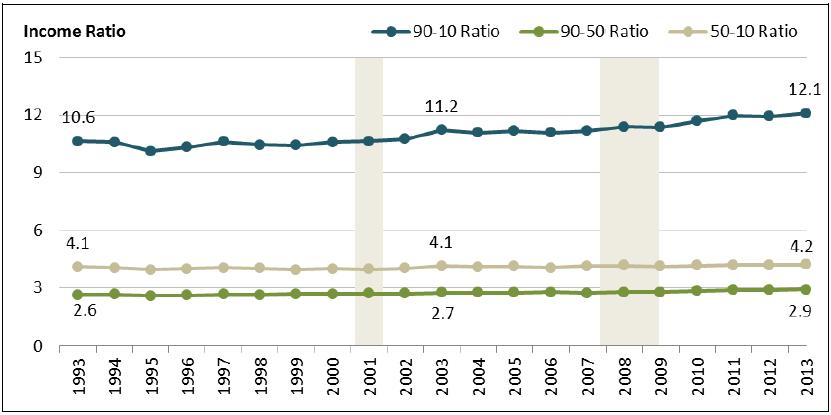
Notes: Income in this figure refers to household money income as defined by the Census Bureau: pre-tax cash income received by households on a regular basis from market and nonmarket sources. Money income excludes periodic income, such as capital gains, and in-kind transfers. Periods of recession are shaded in gray. Recession data are from the National Bureau of Economic Research, http://www.nber.org/cycles.html, and reflect the 2001 recession (March 2001-November 2001) and the 2007-2009 recession (December 2007-June 2009).Figure 7 shows the evolution of 90-10, 90-50, and 50-10 income ratios between 1993 and 2013, and can be used to assess relative experiences of income groups over time. Households at the 90th, 50th, and 10th percentiles are traditional stand-ins for the top, middle, and bottom of the income distribution. Movement across these ratios, therefore, can be used to gauge changes in the relative experience of top to bottom (90-10 ratio), top to middle (90-50 ratio), and middle to bottom (5010 ratio). All ratios increased between 1993 and 2013, indicating that the income groups are moving farther apart from each other. The most pronounced change is in the 90-10 ratio, which increased from 10.6 to 12.1 (or approximately 14%).
Figure 7. Income Ratios, 1993-2013

Click to enlargeSource: Figure created by CRS based on data from U.S. Census Bureau, Current Population Survey, Annual Social and Economic Supplements, l993-20l3, available at http://www.census.gov/hhes/www/income/data/index.html.
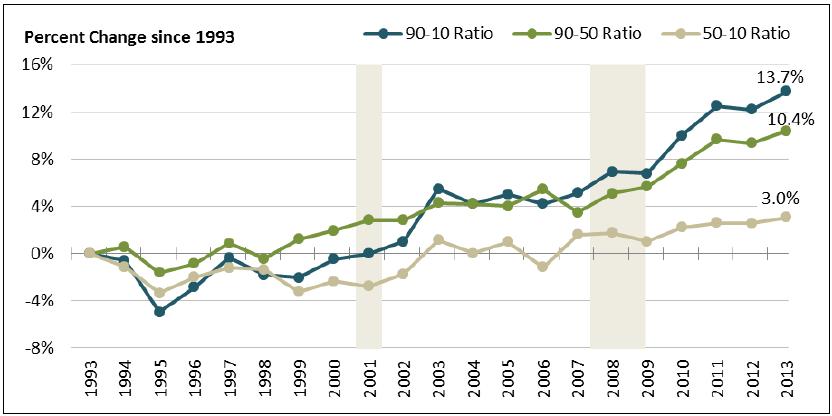
Notes: Income in this figure refers to household money income as defined by the Census Bureau: pre-tax cash income received by households on a regular basis from market and nonmarket sources. Money income excludes periodic income, such as capital gains, and in-kind transfers. Periods of recession are shaded in gray. Recession data are from the National Bureau of Economic Research, http://www.nber.org/cycles.html, and reflect the 2001 recession (March 2001-November 2001) and the 2007-2009 recession (December 2007-June 2009).An interesting question, and one that is not immediately apparent from Figure 7, is whether growth in the 90-10 ratio reflects growing distance between the bottom and middle households or relatively high-income growth at the very top (i.e., a further extension of the right tail). To address this question, income ratios are sometimes expressed (and graphed) in terms of cumulative percentage change from an anchor year. Figure 8 does just that. It converts the same data into the cumulative percentage change since 1993. All ratios show growth over their 1993 values, but more notably, the 90-50 ratio growth tracked closely with the 90-10 ratio while the 5010 ratio exhibits low to no growth (over the 1993 ratio). The take away from these patterns is the rise in the 90-10 ratio is driven by growth at the top half (90-50) of the distribution (i.e., the extension of the right tail).
Figure 8. Cumulative Percentage Change in Income Ratios, 1993-2013

Click to enlargeSource: Figure created by CRS based on data from U.S. Census Bureau, Current Population Survey, Annual Social and Economic Supplements, 1993-2013, available at http://www.census.gov/hhes/www/income/data/index.html.
Notes: Income in this figure refers to household money income as defined by the Census Bureau: pre-tax cash income received by households on a regular basis from market and nonmarket sources. Money income excludes periodic income, such as capital gains, and in-kind transfers. Periods of recession are shaded in gray. Recession data are from the National Bureau of Economic Research, http://www.nber.org/cycles.html, and reflect the 2001 recession (March 2001 -November 2001) and the 2007-2009 recession (December 2007-June 2009).Figure 9 compares quintile income shares across 1993, 2003, and 2013, and reveals growing concentration of U.S. household income at the top of the distribution over the past 20 years. The top of the distribution held a disproportionate share of income in 1993, 2003, and 2013. The share of income among the top 20% of the distribution grew from 48.9% in 1993 to 49.8% in 2003 and to 51% in 2013. The shares of total income held by each of the four lower quintiles fell between 1993 and 2003, and again between 2003 and 2013.
Figure 9. Quintile Shares of Total Income, 1993-2013

Click to enlargeSource: Figure created by CRS based on data from U.S. Census Bureau, Current Population Survey, Annual Social and Economic Supplements, 1993-2013, available at http://www.census.gov/hhes/www/income/data/index.html.
Notes: Income in this figure refers to household money income as defined by the Census Bureau: pre-tax cash income received by households on a regular basis from market and nonmarket sources. Money income excludes periodic income, such as capital gains, and in-kind transfers.Figure 10 translates the movement in income shares across quintiles into the percentage change in quintile share since 1993. This presentation can help identify trends and changes in trends. Figure 10 suggests 2000 was a turning point of sorts for the top quintile and bottom three quintiles. Prior to 2000, each quintile fluctuated close to a 2% increase or decrease over its 1993 share. After 2000, Figure 10 shows a relatively steady climb in the income share held by the top quintile, paired with declining shares among the bottom three quintiles; the fourth quintile continued to fluctuate steadily around a 2% cumulative change. It is important to note that data points shown in the line graphs in Figure 10 represent cumulative change since 1993; they do not describe year-by-year (i.e., annual) percentage change (except for 1994) nor depict percentage point changes.
Figure 10. Cumulative Change in Quintile Shares of Total Income Since 1993

Click to enlargeSource: Figure created by CRS based on data from U.S. Census Bureau, Current Population Survey, Annual Social and Economic Supplements, 1993-2013, available at http://www.census.gov/hhes/www/income/data/index.html.
Notes: Income in this figure refers to household money income as defined by the Census Bureau: pre-tax cash income received by households on a regular basis from market and nonmarket sources. Money income excludes periodic income, such as capital gains, and in-kind transfers. Periods of recession are shaded in gray. Recession data are from the National Bureau of Economic Research, http://www.nber.org/cycles.html, and reflect the 2001 recession (March 2001 -November 2001) and the 2007-2009 recession (December 2007-June 2009).Figure 9 and Figure 10 present the same information in visually different ways. In comparing the two charts, the decline in income share among the lower quintiles appears much more pronounced in Figure 10. This happens because percentage point changes (Figure 9) reflect an absolute change in percentage points, whereas the percentage change shown in Figure 10 is a relative difference that is sensitive to base (i.e., value in 1993). |35| Since the lowest quintile has a small base (3.6% in 1993), even small absolute changes in percentage points will represent a large percentage change. For example, Figure 10 shows an 11.1% fall in income share for the lowest quintile between 1993 and 2013, but the same change is shown in Figure 9 as a 0.4 percentage point decrease.
Comparing Income by Geographical Location
Variation in Median Household Income across States
Comparing income statistics across U.S. states can reveal interesting economic and distributional variation that is otherwise masked by national-level data. Figure 11 maps state median income in 2013. Some broad geo-economic patterns emerge. For example, a band of states in the southern part of the country had median income under $45,000 in 2013, while a cluster of states on the northeast coast had median incomes of $60,000 or more in the same year. This difference does not necessarily imply that median households in southern states had three-quarters or less the purchasing power of median households in coastal northeast states, because price levels are also found to fluctuate across states.
Figure 11. Median Household Income by State, 2013

Click to enlargeSource: Figure created CRS based on data from U.S. Census Bureau, Current Population Survey, Annual Social and Economic Supplement, 2013, available at http://www.census.gov/hhes/www/income/data/index.html.
Notes: Income in this figure refers to household money income as defined by the Census Bureau: pre-tax cash income received by households on a regular basis from market and nonmarket sources. Money income excludes periodic income, such as capital gains, and in-kind transfers.Accounting for Regional Price Variation
Income comparisons over time and location can reflect true differences in purchasing power, and they can also reflect differences in price. Adjusting time series income data for inflation is standard practice, as it is generally acknowledged that prices change over time and affect the dollar value of income. Less recognized is the potential for wide variation in prices across geographical divisions. For the United States, the Commerce Department Bureau of Economic Analysis estimates that in 2012, average price levels (for consumption goods and services) in the District of Columbia were more than 18% higher than the national price average, while prices were nearly 14% below the national average in Mississippi (See Figure 12).
Figure 12. BEA Regional Price Parities by State, 2012

Click to enlargeSource: Figure created by CRS using data from the Commerce Department, Bureau of Economic Analysis, "Real Personal Income for States and Metropolitan Areas, 2008-2012," press release, April 24, 2014, https://www.bea.gov/newsreleases/regional/rpp/rpp_newsrelease.htm.
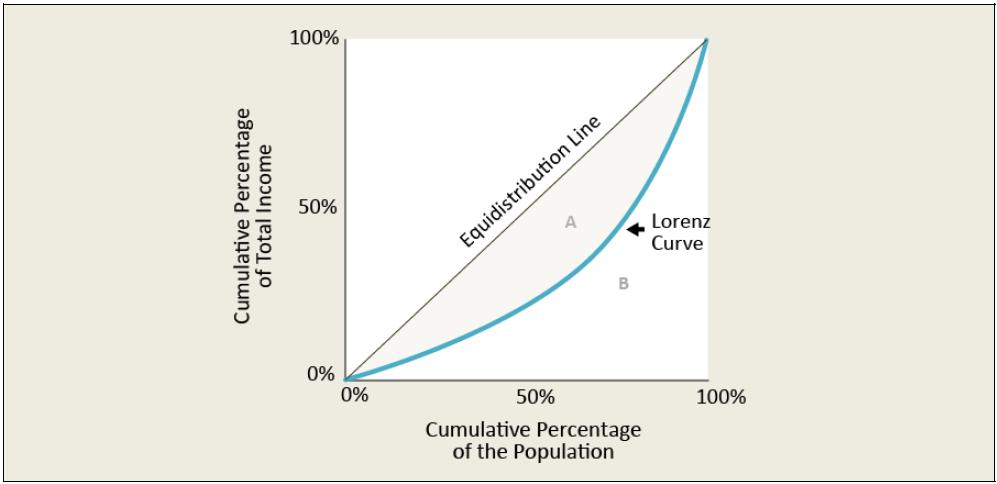
Note: Dark-shaded bars indicate an index greater than 100.The Gini index is a popular summary measure of income dispersion that describes the relationship between the cumulative distribution of income and the cumulative distribution of the population, a relationship depicted by the Lorenz curve. |36| It is used to assess changes in income dispersion for a given population over time and make comparisons across groups, especially international comparisons.
The Lorenz curve (Figure 13) plots the cumulative percentage of the population in ascending order of income (i.e., from poor to rich) on the horizontal axis against the cumulative percentage of total income on the vertical axis. Points along the Lorenz curve indicate the portion of total income held by a particular segment of the population. The straight grey line in Figure 13 shows what the Lorenz curve would look like if total income was equally distributed. Under that scenario, for example, 50% of total income would be held by the (poorest) 50% of the population (point A), 75% of total income would be held by the (poorest) 75% of the population (point B), and so forth. This line is alternately referred to as the line of equality or the equidistribution line. The curved line illustrates the Lorenz curve under a more realistic scenario, in which income is dispersed unevenly across the population. As more income is concentrated at the top of the distribution, the curve pulls farther away from the equidistribution line.
Figure 13. The Relationship Between the Lorenz Curve and Gini Index

Click to enlargeSource: CRS.
The Gini coefficient is the ratio of the area between the Lorenz curve and the equidistribution line (area A) to the total area underneath the equidistribution line (area A + area B). As the Lorenz curve approaches the equidistribution line, area A falls and the Gini index value declines. Perfect equality occurs when the Lorenz curve overlaps the equidistribution line and there is no area between the two curves, reducing the Gini to zero. When a single household holds all income-- the perfect inequality scenario--the Lorenz curve runs along the horizontal axis up until the final percentile where it jumps to 100%. Under this scenario, the area between the equidistribution line and the Lorenz curve and the area underneath the equidistribution line are the same (area A + area B), producing a Gini index value of one.
As demonstrated above, Gini index values range from zero to one, with zero indicating perfect equality (i.e., all individuals hold the same income) and one indicating perfect inequality (i.e., all income is held by one household). It provides a convenient way to compare the distribution of income over time or the income distributions for different groups, with higher values indicating greater dispersion. However, the index has drawbacks as well. For example, the Gini index does not convey information about the shape of the income distribution; several different shapes can yield the same Gini index value. Figure 14 provides an example of two Lorenz curves that both produce a Gini value of 0.20. The Gini is also not perfectly decomposable, which means it is not well-suited for comparing the dispersion of income within groups to the dispersion between groups.
Figure 14. Two Lorenz Curves with the Same Gini Index

Click to enlargeSource: Graph constructed by CRS based on an example provided in Lorenzo Giovanni Bellu and Paolo Liberati, Inequality Analysis: the Gini Index, Food and Agricultural Organization of the United Nations, EASYPOL Module 40, December 2006, http://www.fao.org/tc/easypol.
Notes: Both Lorenz curves yield a Gini index of 0.20Figure 15 plots the Gini index between 1993 and 2013 and shows an upward trend. Over this time period, the Gini index for the United States ranged from 0.450 (in 1995) to 0.477 (in 2011). It was 0.476 in 2013.
Figure 15. Gini Index for the United States, 1993-2013

Click to enlargeSource: Figure created by CRS based on data from U.S. Census Bureau, Current Population Survey, Annual Social and Economic Supplements, 1993-2013, available at http://www.census.gov/hhes/www/income/data/index.html.
Notes: Income in this figure refers to household money income as defined by the Census Bureau: pre-tax cash income received by households on a regular basis from market and nonmarket sources. Money income excludes periodic income, such as capital gains, and in-kind transfers. Periods of recession are shaded in gray. Recession data are from the National Bureau of Economic Research, http://www.nber.org/cycles.html, and reflect the 2001 recession (March 2001 -November 2001) and the 2007-2009 recession (December 2007-June 2009).[Source: By Sarah A. Donovan, Congressional Research Service, R43897, Washington D.C., 05Feb15. Sarah A. Donovan is an Analyst in Labor Policy.]
Appendix A. Describing Incomes at the Top of the Distribution
Survey data, like the CPS-ASEC used by the Census Bureau to describe the distribution of household money income cannot be used to identify with certainty the highest and lowest earners in the population (See "Census Data"). IRS data are superior for studying incomes at the top, but privacy rules limit the information the IRS can share publicly about filers, though it does provide some information. For example, IRS is required by law to report (in aggregate) on the number of filers with adjusted gross incomes above $200,000, and it produces occasional reports on the top 400 filers, considered in aggregate and with identifying information removed. |37|
Through data agreements with both agencies, the Congressional Budget Office (CBO) is able to combine CPS and IRS data to create a more comprehensive picture of the income distribution than could be obtained from either data set used alone. As part of their analysis, CBO describes the distribution of incomes within the top 20% of households.
Figure A-1 shows average after-tax income within the top quintile for 2011 as reported by CBO. CBO data indicate a wide range of incomes at the top of the income spectrum. The top 20% of households received $188,200 on average in after-tax income in 2011. Average income among the top 1% was $1,031,900. While mean income among the top 1% is high relative to the overall quintile mean, it is likely to lie far below incomes of the highest earners. For reference, IRS analysis of the top 400 filers in 2009 revealed that average adjusted-gross income among them was $202 million. |38|
Figure A-1. Mean After-Tax Income within the Top Income Quintile, 2011

Click to enlargeSource: Prepared by CRS using data from the Congressional Budget Office, The Distribution of Household Income and Federal Taxes, 2011, December 2014, Supplemental Data, available from https://www.cbo.gov/publication/49440.
Notes: Income in this figure refers to after-tax household income as defined by CBO: the sum of market income and government transfers, less federal tax liabilities. CBO defines market income as labor income, business income, capital gains realized from the sale of assets, capital income excluding capital gains, and income received in retirement for past services or from other sources. CBO defines government transfers as both cash and in-kind benefits.
Appendix B. Summary Indicators Reported by Census
The U.S. Census Bureau publishes several summary measures of income dispersion in its annual Income and Poverty in the United States report: the Gini index, mean log deviation of income (MLD), Theil index, and Atkinson index. These indicators differ from the measures described in the main body of this report in that they do not convey descriptive details on the experience of the typical household, the range of incomes, or the shape of the distribution, but instead use information on the full distribution to characterize overall income dispersion (i.e., they are relative measures used to assess departure from a perfectly equal distribution of income). While the Gini is familiar to many (and discussed in this report--see "Gini Index"), the other three measures are less so. This appendix provides an overview of the MLD, Theil, and Atkinson indices, explaining their basic properties and interpretation, and the value they bring to analysis of the income distribution.
Generalized Entropy Indices: MLD and Theil Index
General entropy (GE) indices are a family of relative inequality measures that are based on ratios of incomes to the mean. A sensitivity parameter--typically identified using the Greek letter alpha--adjusts the weight the index gives to various portions of the distribution and distinguishes members of the broader class of GE measures. Two of the most popular GE measures are the MLD and Theil index, which are defined when the sensitivity parameter is set to zero and one, respectively. They are bounded from below by zero, the value that communicates perfect income equality. Both indices rise in value as the dispersion of income increases; higher values indicate a wider dispersion (i.e., more unequal distribution). Unlike the Gini, general entropy indices are not capped at one.
The MLD and Theil index share several attractive features. They are scale invariant, meaning that the value does not change when all incomes are multiplied by a constant. This is helpful because it means, for example, that the measure is not sensitive to currency conversion. They also respond in an intuitive way to transfers of income within a distribution. Namely, they will register more dispersion when income is transferred from households at the bottom to those at the top. |39| Finally, they are perfectly decomposable by subgroups. Both measures permit within and between components to be identified separately (e.g., they can be used to assess the extent to which a change in income dispersion is due to changes within U.S. states and how much can be explained by changes between states).
The MLD and Theil differ, however, in their sensitivity to changes at various parts of the income distribution. MLD is sensitive to changes at the bottom of the distribution, and will be more responsive than the Theil index to increased dispersion among low to middle incomes. The Theil index, on the other hand, will rise faster than the MLD as incomes at the top of the distribution grow disproportionately. |40| As such, it is possible to compare changes in income dispersion across portions of the distribution (lower tail, middle, or upper tail) by observing how the MLD and Theil index change over time for a given income distribution.
The Atkinson Index
The Atkinson index is a welfare-based measure. It uses a specific mathematical function to quantify the "social welfare" of a given income distribution and compares it to the value the same social welfare function would have if total income was distributed with perfect mathematical equality. The interpretation given to the numerical value of the index is the proportion of total income a society would be willing to forfeit to achieve a perfectly equal distribution. For example, consider a society with 100 individuals and a total (societal) income of $1 million. An Atkinson index of 0.10 indicates that this society would be equally content with 90% of total income (i.e., $900,000) if it were distributed equally among all 100 members (i.e., all members earn $9,000), as they are with the actual distribution of (actual) total income. The Atkinson index values range from 0 to 1, with 0 indicating that total income is distributed with perfectly mathematical equality (i.e., society would be willing to give up none of its total income to achieve an equal distribution, because they are already there).
Like general entropy indices, the Atkinson index is a parameterized measure. The Atkinson sensitivity parameter--denoted by the Greek letter epsilon and often called the inequality aversion parameter--varies the priority applied to incomes at the lower end of the distribution in the social welfare function. As epsilon increases, so does the weight given to lower-income households and the value of the Atkinson index for a given income distribution.
Like the MLD and Theil index, the Atkinson index is scale invariant, meaning that the index value does not change when all incomes are multiplied by a constant. It also registers more inequality, for a given inequality aversion parameter, as income is transferred from the bottom to the top of the income distribution. Unlike the MLD and Theil index, however, the Atkinson index is not easily decomposable into within and between components. |41|
Notes:
1. For a related discussion of U.S. income distribution trends, see CRS Report RS20811, The Distribution of Household Income and the Middle Class, by Craig K. Elwell. [Back]
2. This report focuses on income. It does not address the measurement and distribution of wealth. Although income and wealth concepts are closely related, they are not the same. Income refers to a flow of resources, some of which are consumed in the present period and the remainder (if any) added to the stock of resources, i.e., wealth. [Back]
3. Studies that compare income definitions and levels of aggregation find that definitional differences matter to income levels, distribution, and the tracking of income trends. For example, see Congressional Budget Office, The Distribution of Household Income and Federal Taxes, 2010, December 2013, http://www.cbo.gov/publication/44604; and Richard V. Burkhauser, Jeff Larrimore, and Kosali Simon, A "Second Opinion" on the Economic Health of the American Middle Class, National Bureau of Economic Research, Working Paper 17164, June 2011, http://www.nber.org/papers/w17164. [Back]
4. There is also some debate over whether income or monetized consumption is the more appropriate measure of living standards. Consumption may more accurately reflect purchasing power, including a household's ability to provide for basic needs. Looking at income alone can mask the economic effects of uncertainty (e.g., risk of job loss), capital loss (e.g., foreclosure), and large differences in prices. These events affect day-to-day economic security and can result in reduced consumption even while income remains steady. In contrast, a drop in income does not necessarily translate into consumption loss if households spend out of their savings or prices fall, or if the measure of income does not include transfer payments (e.g., social programs) or other, informal forms of insurance (e.g., family support networks). [Back]
5. The Current Population Survey (CPS) Table Creator allows users to view a range of statistics using its pre-defined alternative income measures and construct their own income measures by selecting from among 42 Census-defined income components. The CPS Table Creator is available online from http://www.census.gov/cps/data/cpstablecreator.html. [Back]
6. Capital gains and losses are included conceptually by Census in their definitions for disposable income and market income, but Census no longer produces estimates of capital gains and losses. The last year for which capital gains and losses estimates are available from the CPS Table Creator is 2007 (data collected in 2008). The decision to halt production of these estimates was influenced by the two-year delay in access to IRS's individual income tax records (the primary data source for capital gains and losses estimates). [Back]
7. The Survey of Consumer Finance (SCF, see footnote 14) data show that households in the top income group are more likely to hold public stock (a capital gains earning asset) and have higher mean stockholding values than households at the bottom of the distribution. In 2013, the stock ownership rate among families in the lower 20% of the income distribution was 4.2%, whereas it was 45.4% for families in the top 10% of the income distribution. Preliminary SCF numbers reveal that, among families that held stock, the mean value of stockholdings for families in the bottom 20% of the income distribution was $55,500 in 2013, whereas it was $694,200 among families in the top 10%. Board of Governors of the Federal Reserve System, "2013 Survey of Consumer Finances, Historic Tables and Charts Based on Internal Data," September 4, 2014, http://www.federalreserve.gov/econresdata/scf/scfindex.htm. [Back]
8. See, for example, Philip Armour, Richard V. Burkhauser, and Jeff Larrimore, "Levels and Trends in U.S. Income and its Distribution: A Crosswalk from Market Income towards a Comprehensive Haig-Simons Income Approach," Southern Economic Journal, vol. 81, no. 2 (2014), pp. 271-293. [Back]
9. A discussion of both viewpoints is provided by Thomas B. Edsall, "What if We're Looking at Inequality the Wrong Way?," The New York Times, June 26, 2013, http://opinionator.blogs.nytimes.com/2013/06/26/what-if-were-looking-at-inequality-the-wrong-way/. [Back]
10. The Congressional Budget Office (CBO) compared the 2011 U.S. income distribution before and after accounting for taxes, finding a "slightly more" compressed distribution when tax deductions and credits are applied. CBO, The Distribution of Household Income and Federal Taxes, 2011, November 2014, https://www.cbo.gov/publication/49440. [Back]
11. Census produces annual estimates of the fungible value of Medicaid or Medicare, but does not include these estimates in any of their pre-defined income measures. Instead, they permit data users to include Medicare and/or Medicaid estimates when customizing income measures. This value is calculated based on the extent to which the programs free up resources that otherwise could have been used to purchase medical care or insurance. Robert W. Cleveland, Alternative Income Estimates in the United States: 2003, U.S. Census Bureau, P60-288, June 2005, https://www.census.gov/hhes/www/income/publications/cps-reports.html. CBO accounts for health insurance programs, including Medicare, Medicare, and CHIP in its analyses of the U.S. income distribution, using the average cost to the government of providing the benefit. CBO departed from the Census methods of estimating government-provided health insurance in 2012 with its analysis of the 2008 and 2009 U.S. income distributions. Details on CBO's treatment of health care benefits are reported in CBO, The Distribution of Household Income and Federal Taxes, 2008 and 2009, July 2012, http://www.cbo.ogv/publication/43373. [Back]
12. The Census Bureau, for example, provides equivalence-adjusted estimates for some but not all of its income dispersion estimates to account for differences in membership numbers and composition (i.e., that children consume less on average than adults, and the impacts of economies of scale that derive from the sharing of resources and expenses within families). See Carmen DeNavas-Walt and Bernadette D. Proctor, Income and Poverty in the United States: 2013, U.S. Census Bureau, Current Population Reports P60-249, September 2014, http://www.census.gov/. The CBO also adjusts household income for membership, treating adults and children equally. See CBO, The Distribution of Household Income and Federal Taxes, 2011, November 2014, https://www.cbo.gov/publication/49440. [Back]
13. The Panel Survey of Income Dynamics (PSID), which is run by the University of Michigan, is a popular (and nongovernment) source of data on incomes in the United States. For more information on the PSID, see http://psidonline.isr.umich.edu/. [Back]
14. The SCF is another source of data on income in the United States. The SCF is a cross-sectional survey administered every three years under the auspices of the Federal Reserve Board to collect information on the assets and liabilities (among other characteristics) of U.S. households. Although the SCF collects income data, its main strength is the span and detail of information collected on household wealth. Additional information is available at http://www.federalreserve.gov/econresdata/scf/aboutscf.htm. [Back]
15. CBO uses both Census and IRS data in its analysis of the distribution of household income and federal taxes. CBO does not provide public access to its household-level data, but rich supplemental data tables on the CBO website provide useful details and complement the analysis provided in its reports. Because of delayed access to IRS data, the CBO analysis applies to a past-year(s) income distribution. The most recent report describes the 2011 income distribution. For more information, see CBO, The Distribution of Household Income and Federal Taxes, 2011, December 2014, Supplemental Data, available at https://www.cbo.gov/publication/49440. [Back]
16. The ASEC is also referred to as the March Supplement because it is administered largely in March of each year. [Back]
17. Older versions of this report also looked at health insurance coverage. The Census Bureau began reporting separately on health insurance in 2014. For Census statistics on income and poverty for 2013, see Carmen DeNavas-Walt and Bernadette D. Proctor, Income and Poverty in the United States: 2013, U.S. Census Bureau, Current Population Reports P60-249, September 2014, http://www.census.gov/. [Back]
18. Variable censoring at the point of data capture and processing for the CPS-ASEC sample is likely to be rare. Based on data collected in the 2000 survey, Welniak reports that no households in the sample reported earnings income above the data-capture limit and only 26 households reported earnings income above the processing limit. See Edward J. Welniak, Measuring Household Income Inequality Using the CPS, Internal Revenue Service, Statistics of Income Division, Special Studies in Federal Tax Statistics, 2003, pp. 3-13. [Back]
19. The CPS-ASEC records information for dozens of income categories for each individual aged 15 or older, for up to 16 persons per household. It collects data on four categories of earned-income: (1) wage and salary income from longest job-held, (2) other wage and salary income, (3) nonfarm self-employment income, and (4) farm self-employment income. [Back]
20. Additional data editing is applied to public-release data to preserve confidentiality of the CPS-ASEC survey respondents. Historically, income data were censored above a Census-determined maximum value. This maximum value changed from year to year, and it was typically selected to be the 97th percentile of income (for a particular income source). Incomes greater than the maximum value were either replaced by the maximum value (prior to 1996) or the mean of values above the maximum (1996-2010). Starting in 2011, Census employed a new method to provide confidentiality protections called rank proximity swapping. Using this method, (edited) income values are swapped between individuals with similar income ranks for all individuals in the top 3% of income. For more information, see Carmen DeNavas-Walt and Bernadette D. Proctor, Income and Poverty in the United States: 2013, U.S. Census Bureau, Current Population Reports P60-249, September 2014, p. 61. [Back]
21. The 2014 version of the CPS-ASEC was redesigned with this limitation in mind, and it attempts to measure interest, dividend, and pension income more accurately. [Back]
22. The SCF (see footnote 14) also provides information on incomes and assets at the top of the distribution. [Back]
23. For more information, see CRS Report R40411, The Economic Effects of Capital Gains Taxation, by Thomas L. Hungerford. [Back]
24. Charles F. Manski, "Income Tax and Labor Supply: Let's Acknowledge What We Don't Know," VOX (CEPR), August 23, 2012, http://www.voxeu.org/article/income-tax-and-labour-supply-let-s-acknowledge-what-we-don-t-know. [Back]
25. Most data are from Carmen DeNavas-Walt and Bernadette D. Proctor, Income and Poverty in the United States: 2013, U.S. Census Bureau, Current Population Reports P60-249, September 2014. Additional Census data are taken from supplemental tables, available at http://www.census.gov/hhes/www/income/data/incpovhlth/2013/index.html. [Back]
26. The most recent year of data available is 2013. [Back]
27. For more information, see http://www.bls.gov/cpi/cpirsdc.htm. [Back]
28. This is not to say that the mean is without value. Among other uses, the mean provides a meaningful indicator of total group income, adjusted for population size. It can be used to compare resources across groups when distribution within groups is not of primary interest. [Back]
29. Because income by some definitions can be negative, the range is not necessarily equivalent to the income of the top earner (i.e., as it would if the bottom income by definition was zero). [Back]
30. Money income can take on negative values because it includes income from business sources (such as commercial farms), which can record losses. [Back]
31. Likewise, a left-skewed distribution will have a mean-to-median ratio that is less than one. [Back]
32. Mean and median household incomes were $65,766 and $49,594 (in 2013 CPI-U-RS adjusted dollars), respectively, in 1993. In 2013, mean household income was $72,641 and median household income was $51,939. [Back]
33. A rise in the mean-to-median ratio does not necessarily imply growth at the top, since growth in income below the median can push up the mean as well. If income among low-income households rises disproportionately and median income growth does not match pace, the ratio can rise without an accompanying rise in the spread of data. [Back]
34. Two important notes are in order. First, this does not mean that all households within a given quintile experienced income growth. Some households' incomes grew at rates above their quintile average, some grew at rates below their quintile average, and some experienced income loss. Second, households do not necessarily stay in a given quintile from year to year. So, for example, the households that comprise the middle quintile in 2013 may not be the households that comprise the middle quintile in 2003 or 1993. Analysis of microdata is needed to examine income dynamics. [Back]
35. To be clear, the percentage points shown in Figure 9 are a relative measure that describe quintile shares of total income (i.e., how "the pie" is divided across household income groups). But the change in percentage point is measured in absolute terms, not as a percentage of its base value. [Back]
36. Mathematically, the Gini coefficient is based on the average absolute difference between all random pairs of incomes normalized by the mean. [Back]
37. The Tax Act of 1976 (P.L. 94-455) requires the IRS to publish information on individual tax returns for $200,000 or more; for more information, see http://www.irs.gov/uac/SOI-Tax-Stats-Individual-High-Income-Tax-Returns. [Back]
38. See http://www.irs.gov/uac/SOI-Tax-Stats-Top-400-Individual-Income-Tax-Returns-with-the-Largest-Adjusted-Gross-Incomes. [Back]
39. This is known as the principle of transfer, one of several measures used to assess income dispersion measures. [Back]
40. More generally, when the sensitivity parameter is small and positive, the index is more responsive to changes at the bottom of the distribution. As it takes higher, positive values, the index is more sensitive to changes at the top of the distribution. [Back]
41. The Atkinson index can be transformed into a generalized entropy measure that is perfectly decomposable into within and between components. The formula for this transformation and additional information is in Lorenzo Giovanni Bellu and Paolo Liberati, Policy Impacts on Inequality: Welfare-based Measures of Inequality, The Atkinson Index, Food and Agriculture Organization of the United Nations, EASYPol Module 50, December 2006. [Back]
 | This document has been published on 02Apr15 by the Equipo Nizkor and Derechos Human Rights. In accordance with Title 17 U.S.C. Section 107, this material is distributed without profit to those who have expressed a prior interest in receiving the included information for research and educational purposes. |